El riesgo de los grandes modelos lingüísticos: convertirse en loros estocásticos
Por Esther Sánchez García y Michael Gasser
Volume 24, Number 2, Don’t Be Evil
Read the original article in English here.
“La Inteligencia Artificial ni es artificial ni es inteligente”. —Kate Crawford
En octubre de 2020, cuatro autoras presentaron un artículo a la ACM Conference on Fairness, Accountability, and Transparency titulado Sobre los peligros de los loros estocásticos: ¿pueden los modelos del lenguaje ser demasiado grandes?, criticando la investigación actual sobre el procesamiento del lenguaje natural.1 Lo hacen en referencia a los intentos de desarrollar máquinas capaces de comprender el texto y el lenguaje hablado, lo que ha experimentado una gran expansión en particular con el advenimiento de modelos de lenguaje estadístico cada vez más sofisticados, tal y como las autoras documentan ampliamente en su trabajo.
Nueve días antes de que el artículo fuera aceptado para la conferencia, Timnit Gebru, una de las autoras, fue despedida de su puesto como codirectora del equipo de ética de Google después de negarse a retirar su nombre del artículo. Otra autora, y también codirectora del equipo de Ética de Gebru, Margaret Mitchell, fue despedida dos meses después. Por estas acciones, Google recibió fuerte críticas por parte de los medios, por ejemplo desde el NYT y Wired se habló ampliamente de ello.2 Desde entonces, tanto dentro de la empresa como fuera de ella, muchos colegas han mostrado un fuerte apoyo a Gebru y Mitchell.3
La importancia del artículo va más allá de las conclusiones puramente científicas, ya que ha iniciado un discurso sobre las implicaciones sociales de la tecnología de procesamiento del lenguaje natural.
Pero, ¿qué son los modelos de lenguaje? ¿Y por qué querría Google desvincularse de las críticas que se les hacen?
Un poco de contexto técnico
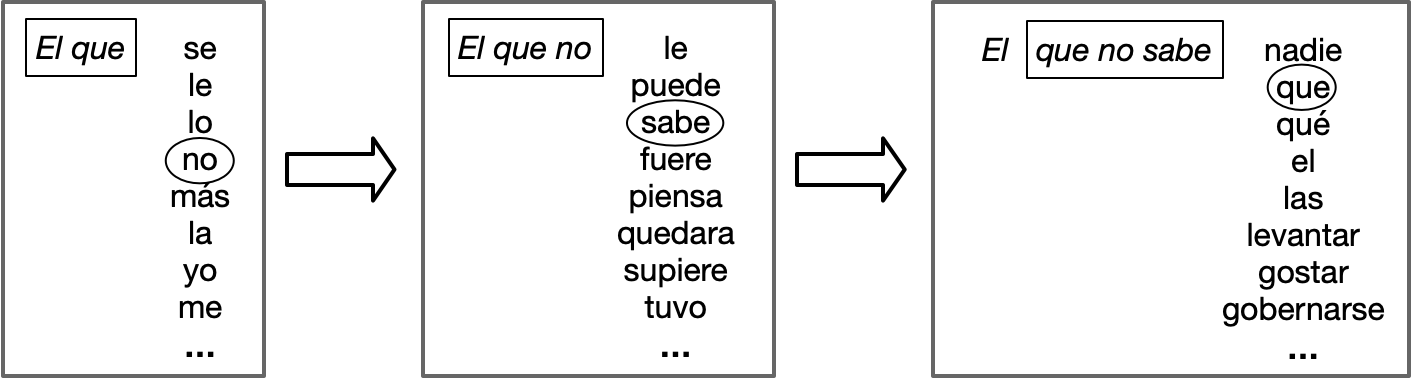
Un modelo del lenguaje es un registro, para un texto dado (denominado corpus), de las probabilidades de que las palabras aparezcan en contextos particulares en ese corpus.4 Por ejemplo, usando como corpus Don Quijote de la Mancha, un modelo de lenguaje nos indicaría que el texto el que no es seguido por las palabras le, puede y sabe con mayor frecuencia. Es sencillo escribir un programa que utiliza un corpus y cuenta todas las apariciones de palabras y sus contextos, lo que da como resultado un sistema llamado modelo n-grama.
Sin embargo, muchos modelos hoy en día son redes neuronales.5 Estas pueden aprender a asociar de manera eficiente contextos relativamente largos, de hasta más de dos mil palabras, con las probabilidades de que diferentes palabras los sigan. Para hacer esto, se les debe entrenar con un corpus muy grande, de cientos de miles de millones de palabras. Las asociaciones entre contextos y palabras siguientes se implementan en la red en forma de parámetros. Estos modelos son grandes en el sentido de que escalan hasta billones de parámetros.
¿Para qué sirve un modelo del lenguaje? Por un lado, puede generar textos basados en las estadísticas de un corpus. Comenzamos un texto, por ejemplo, con las palabras El que. Nuevamente utilizando Don Quijote como nuestro corpus, nuestro modelo nos dice que 284 palabras son posibles para continuar. Para nuestro texto, podríamos elegir el más común, se, pero como lo que queremos es crear un texto diferente cada vez que ejecutamos el generador, así que elegimos la siguiente palabra estocásticamente. Esto quiere decir que la elegimos mediante un método estadístico que consiste en el equivalente a lanzar un dado de 284 lados que está predispuesto a aterrizar según la probabilidad de que la palabra esté a continuación. Digamos que nuestro dado aterriza en el lado que representa la palabra no. A continuación, le preguntamos a nuestro modelo qué palabras pueden seguir a El que no y continuamos hasta tener la cantidad de texto deseada. (Ver Figura 1). Usando un modelo del lenguaje neuronal con una gran cantidad de parámetros entrenados con un corpus muy grande, el resultado se parece sorprendentemente al lenguaje real.
Y por otro lado, estos modelos pueden tener otras funciones además de generar texto. Tareas como la traducción automática, respuesta a preguntas y reconocimiento automático de voz, se basan en las propiedades estadísticas básicas de un idioma. Si entrenamos un modelo neuronal mediante un corpus muy grande, podemos reutilizarlo para otras tareas simplemente indicándole cómo resolverlas. Esto permite a quienes realizan investigaciones no tener que comenzar desde cero en cada nueva tarea.
Los modelos neuronales basados en cantidades masivas de datos se están volviendo cada vez más populares dentro de la investigación en procesamiento de lenguaje natural. En palabras de las autoras, quienes investigan en Google (y en otros lugares), parecen estar operando según el principio «cuánto más, mejor». Se está impulsando exageradamente la investigación, motivado por el desempeño de unos sistemas evaluados con un pequeño conjunto de medidas arbitrarias y muy alejadas de la realidad. Esto ha desencadenado una carrera, con competidores como Google, Facebook, Microsoft, OpenAI o la Academia de Inteligencia Artificial de Beijing para desarrollar nuevos tipos de redes neuronales y construir modelos del lenguaje cada vez más grandes.6
El problema
El artículo se centra en tres problemas de esta tecnología: el coste ambiental, la posibilidad de que las personas seamos engañadas y la incorporación de sesgos mediante los datos de entrenamiento y que se ven reflejados en el resultado final.
Entrenar un gran modelo neuronal ( lo que conlleva ajustar gradualmente los miles de millones o billones de parámetros hasta que la red alcance un nivel determinado de rendimiento) es una tarea enorme, que cuesta millones de dólares y requiere una gran cantidad de energía. Mientras que un ser humano es responsable de cinco toneladas de CO2 al año, el entrenamiento de un modelo de esas características emite 284 toneladas.7 Además, dado que la potencia informática necesaria para entrenar modelos cada vez más grandes se ha multiplicado por trescientas mil veces en seis años, solo podemos esperar que aumenten las consecuencias medioambientales negativas de estos modelos.
¿Quizás todo este CO2 valga la pena? No hay duda de que el rendimiento de los grandes modelos de lenguaje es impresionante. Los generadores de lenguaje y los sistemas de traducción automática basados en estos sistemas producen un texto que se parece mucho al producido por una persona. Pero, ¿esto es algo bueno? La comunicación humana tiene como finalidad dar sentido a lo que otros dicen o escriben, por lo que tenemos una fuerte tendencia a encontrar coherencia y significado incluso cuando no están ahí. En el caso de texto producido por un modelo, no está ahí. Los modelos del lenguaje no conocen nada más que información probabilística sobre secuencias de palabras en el corpus con el que fue entrenado. No hay un objetivo comunicativo, ningún significado genuino detrás del texto que producen: son loros estocásticos y en las manos equivocadas, podría ser un loro verdaderamente peligroso. Por ejemplo, podríamos producir grandes cantidades de texto aparentemente coherente sobre cualquier un tema, haciendo que parezca que hay un gran interés entre el público por hablar de ello. O podríamos generar innumerables páginas de comentarios sobre una noticia falsa, apoyando la información y convertirlo en una realidad social.
Debido a que el texto generado por los grandes modelos del lenguaje parece genuino, es razonable observar más de cerca el contenido, lo que estos modelos saben. Claramente, están limitados por los datos en los que están adiestrados. Nuestro modelo simple entrenado en Don Quijote obviamente estaría sesgado hacia una perspectiva particular del mundo y no sabría nada acerca de los desarrollos de los últimos cuatrocientos años. Aunque puede ser menos obvio, un modelo entrenado con los datos disponibles en Internet también tendría sesgos incorporados, porque estos datos no son representativos de lo que toda la humanidad sabe y cree. Por ejemplo, mientras que Wikipedia es una fuente importante de datos para entrenar modelos del lenguaje, tan solo entre el nueve y el quince por ciento de los wikipedistas son mujeres. Otra fuente importante de datos es Reddit, donde el setenta por ciento de los usuarios son blancos y el sesenta y cuatro por ciento tienen menos de treinta años. Además, el acceso a Internet en sí es extremadamente desigual.8 Según Our World in Data, en África subsahariana solo el veinte por ciento de la población usa Internet, mientras que el número se eleva al setenta y ocho por ciento en América del Norte.
Las consecuencias
El trabajo reconoce algunas iniciativas para compensar el impacto ambiental de la capacitación de modelos del lenguaje, pero ¿realmente vale la pena el esfuerzo de destinar energías, incluso renovables, a este objetivo, sabiendo que los avances de la investigación sirven a las personas más privilegiadas (usuarios de Internet) cuando son los menos privilegiados quienes más sufren las consecuencias del cambio climático?
También son las personas menos privilegiadas quienes se ven perjudicadas por la codificación hegemónica que realizan estos modelos. Una visión que excluye a las personas marginadas y amplifica las voces de quienes ya están sobrerrepresentados. Esto, combinado con el hecho de que los textos generados por estos sistemas parecen reales, junto con la reproducción de sesgos hacia grupos específicos, afianza el sistema actual de opresión y desigualdad.
La confianza excesiva en los textos generados también puede conducir a errores graves e irresponsables. Las autoras relatan un ejemplo revelador en el que un palestino fue arrestado e interrogado por la policía israelí en 2017. Ocurrió después de que un sistema de traducción simultánea tradujera el saludo que había escrito en árabe en su muro de Facebook por la palabra “atacar” en hebreo. La traducción automática nos ofrece acceso a mucha información, pero ¿cuánto podemos confiar en ella en los momentos en que tomamos decisiones que afectan la vida de las personas?
Los grandes conjuntos de datos detrás de estos modelos dan lugar a otro problema: es muy costoso actualizarlos. Como resultado, los modelos permanecen estáticos y, por lo tanto, impiden el cambio social y la evolución de los mismos. La consecuencia es que los grupos de hablantes de idiomas infrarrepresentados encontrarán un muro estático de información cuando intenten incluirse. Con esto estamos restringiendo las posibilidades de cambio social.
Por último, no debería sorprendernos que el trabajo en grandes modelos del lenguaje esté dominado por el inglés, que representa más de la mitad de las páginas web de Internet, aunque sólo el cinco por ciento de la población mundial lo habla como lengua materna. ¿Queremos continuar la hegemonía del inglés y silenciar todos los demás idiomas, incluidos los miles de ellos que no tienen si quiera ningún recurso digital?
Actualmente valoramos la cantidad por encima de la calidad. ¿Qué deberíamos hacer como científicos y como activistas?
Las soluciones
Si vamos a continuar esta línea de investigación, debemos intentar mitigar los diversos riesgos y daños que describen las autoras. Nada de esto es trivial dada la cultura investigadora obsesionada con hasta los más pequeños aumentos en el rendimiento. Una acción inmediata para los investigadores en procesamiento de lenguaje natural es considerar con cautela el compromiso entre la energía requerida y los beneficios esperados. Por otro lado, los conjuntos de datos y los sistemas formados en ellos deben planificarse y documentarse cuidadosamente, teniendo en cuenta no solo el diseño de la tecnología, sino también las personas que la utilizarán o que pueden verse afectadas por ella. En lugar de simplemente obtener cantidades masivas de datos disponibles de Internet, quienes realicen la investigación, deberán dedicar un tiempo considerable a crear conjuntos de datos que sean apropiados para las tareas y, en la medida de lo posible, libres de los sesgos que están presentes en los datos sin filtrar. Desde esta perspectiva, «cuánto más, mejor» se convertiría en algo más parecido a «más vale calidad que cantidad».
Google parece pensar que las críticas y propuestas en el documento amenazan los planes de las Big Tech, ya que expulsaron a su equipo de ética por ello. Visto así, cabe preguntarse si Google (y otros) pueden seguir usando la palabra «ética» para describir las nuevas aplicaciones que implementen a este respecto.
Finalmente, deberíamos preguntarnos si vale la pena perseguir estos enormes modelos del lenguaje. Los conjuntos de datos extremadamente grandes que se requieren, ¿traerán consigo los problemas de sesgo inherentes a los datos que de ninguna manera son representativos de la población? ¿Realmente queremos seguir beneficiando a quienes ya se benefician de este tipo de tecnología y su desarrollo? El tiempo y el esfuerzo de investigación son en sí mismos recursos valiosos. Es hora de dedicarlos a reorientar la investigación en procesamiento de lenguaje natural hacia una comprensión más profunda del significado e intención comunicativa y hacia un trabajo vinculado a las necesidades sociales adaptado a los recursos disponibles.
Un buen ejemplo es el creciente campo dedicado al desarrollo de aplicaciones en contextos de bajos recursos, como se ejemplificó en talleres recientes sobre Traducción Automática y Procesamiento de Lenguaje Natural de bajos recursos para lenguas africanas.9 Por supuesto, esto describe la situación en la que se encuentran la gran mayoría de los idiomas del mundo (y sus comunidades de hablantes). Debido a que los sistemas construidos para este tipo de investigación, por definición, nunca son lo suficientemente grandes, no tienen el costo ambiental asociado con los sistemas descritos en el documento. Y, con el apoyo y la colaboración de las comunidades donde se hablan los idiomas, dicho trabajo tiene el potencial de realizar el objetivo de Language Technology For All, la Organización de las Naciones Unidas para la Educación, la Ciencia y la Cultura.10
Aun así, no deberíamos hacernos ilusiones sobre las grandes tecnológicas. La ética para ellas seguirá siendo una tapadera para los intereses de siempre: ganancias a expensas de las personas marginadas. Las mismas personas que siempre han sufrido. Algo que tanto la comunidad investigadora, al igual que el público en general, ha ignorado. La importancia de Stochastic Parrots va más allá de las propias conclusiones del artículo. Simplemente resaltando los problemas específicos de la investigación en estas tecnologías, expone a Google, Facebook y otras tecnológicas como lo que son: empresas cortoplacistas e interesadas exclusivamente en su propio beneficio. Por mucho que intenten ocultarlo con sus autodenominados equipos de ética.
If you liked this article, please consider subscribing or purchasing print or digital versions of our magazine. You can also support us by becoming a Patreon donor.
Referencias
- Emily M. Bender et al., “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜,” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21 (New York, NY, USA: Association for Computing Machinery, 2021), 610–23.
- Cade Metz and Daisuke Wakabayashi, “Google Researcher Says She Was Fired Over Paper Highlighting Bias in A.I,” The New York Times, December 3, 2020, https://www.nytimes.com/2020/12/03/technology/google-researcher-timnit-gebru.html; Tom Simonite, “What Really Happened When Google Ousted Timnit Gebru,” Wired, June 8, 2021, https://www.wired.com/story/google-timnit-gebru-ai-what-really-happened/.
- Google Walkout For Change, “Standing with Dr. Timnit Gebru — #ISupportTimnit #BelieveBlackWomen,” Medium, December 4, 2020, https://googlewalkout.medium.com/standing-with-dr-timnit-gebru-isupporttimnit-believeblackwomen-6dadc300d382; Megan Rose Dickey, “Google Fires Top AI Ethics Researcher Margaret Mitchell,” TechCrunch, February 19, 2021, http://techcrunch.com/2021/02/19/google-fires-top-ai-ethics-researcher-margaret-mitchell/.
- Daniel Jurafsky and James H. Martin, “N-Gram Language Models,” IEEE Transactions on Audio, Speech, and Language Processing 23 (2018).
- Yoav Goldberg, “A Primer on Neural Network Models for Natural Language Processing,” The Journal of Artificial Intelligence Research 57 (November 20, 2016): 345–420.
- “Natural Language Processing,” Facebook AI, accessed July 9, 2021, https://ai.facebook.com/research/NLP/; Alec Radford et al., “Better Language Models and Their Implications” Open AI (blog), February 14, 2019, https://openai.com/blog/better-language-models/; Coco Feng, “US-China Tech War: Beijing-Funded AI Researchers Surpass Google and OpenAI with New Language Processing Model,” South China Morning Post, June 2, 2021, https://www.scmp.com/tech/tech-war/article/3135764/us-china-tech-war-beijing-funded-ai-researchers-surpass-google-and.
- Hannah Ritchie and Max Roser, “CO₂ and Greenhouse Gas Emissions,” Our World In Data, Oxford Martin School, May 11, 2020, https://ourworldindata.org/co2-emissions.
- Michael Barthel et al., “Reddit News Users More Likely to Be Male, Young and Digital in Their News Preferences,” PEW Research Center, February 25, 2016, https://www.journalism.org/2016/02/25/reddit-news-users-more-likely-to-be-male-young-and-digital-in-their-news-preferences/.
- “Proceedings of the 3rd Workshop on Technologies for MT of Low Resource Languages – ACL Anthology,” ACL Anthology, accessed July 9, 2021, https://aclanthology.org/volumes/2020.loresmt-1/; “Program: Putting Africa on the NLP Map,” ICLR 2020, accessed July 9, 2021, https://africanlp-workshop.github.io/program.html.
- “Homepage,” LT4All: Language Technologies for All, accessed July 9, 2021, https://lt4all.org/en/.